When I was looking through some of my old college files, I found my implementation of calculating n-th Fibonacci sequence back when I took CS 115 under Professor David Naumann.
| |
This recursive implementation has an asymptotic time complexity of O(2**n) which, on my Lenovo T490, starts to take more than a second to compute starting from the 30th sequence!
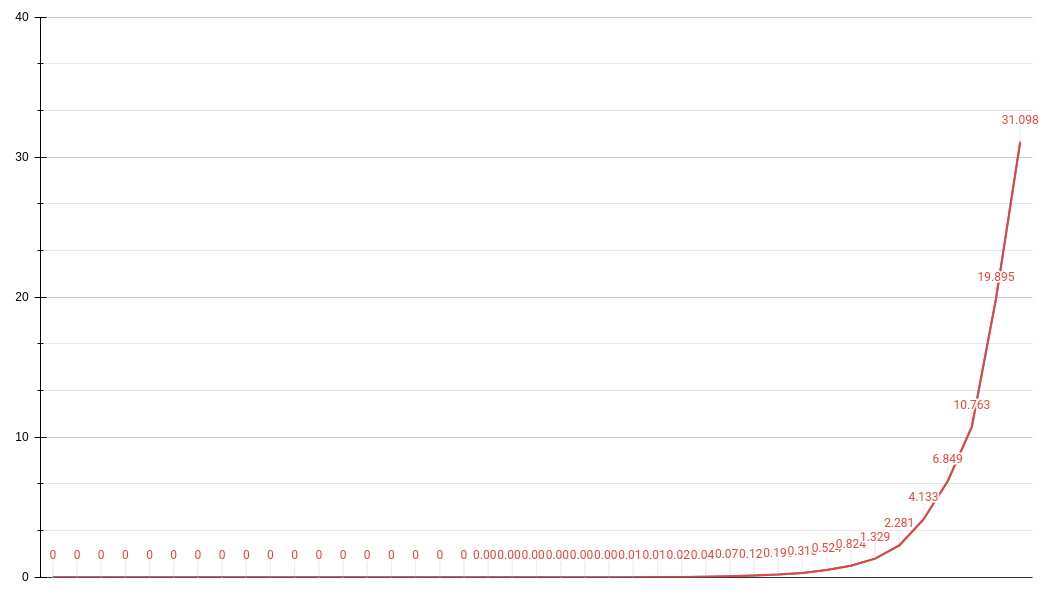
In this blog post, I’ll incrementally improve my old college-implementation.
Improve Performance: Tail-recursion
The biggest problem of using head recursion is it requires all recursive stack frames to be pushed onto the stack. This would mean that function information, method calls, references are kept on the stack before being popped back for final computation. I’m not sure how functional programming languages like Haskell implements recursion, but it must be fast as functional programming paradigms encourage recursion over iterations.
As for the first improvement, I focused on performance. I modified the original implementation to use tail recursion, which executes the pre-recursion statements before going into the next recursive function. This reduces latency as it no longer needs to wait for the last recursion depth and store the information onto the stack. The original implementation uses head recursion which defers any computations by first jumping into the next depth.
| |
This somewhat alleviated the O(2**n) to O(n).
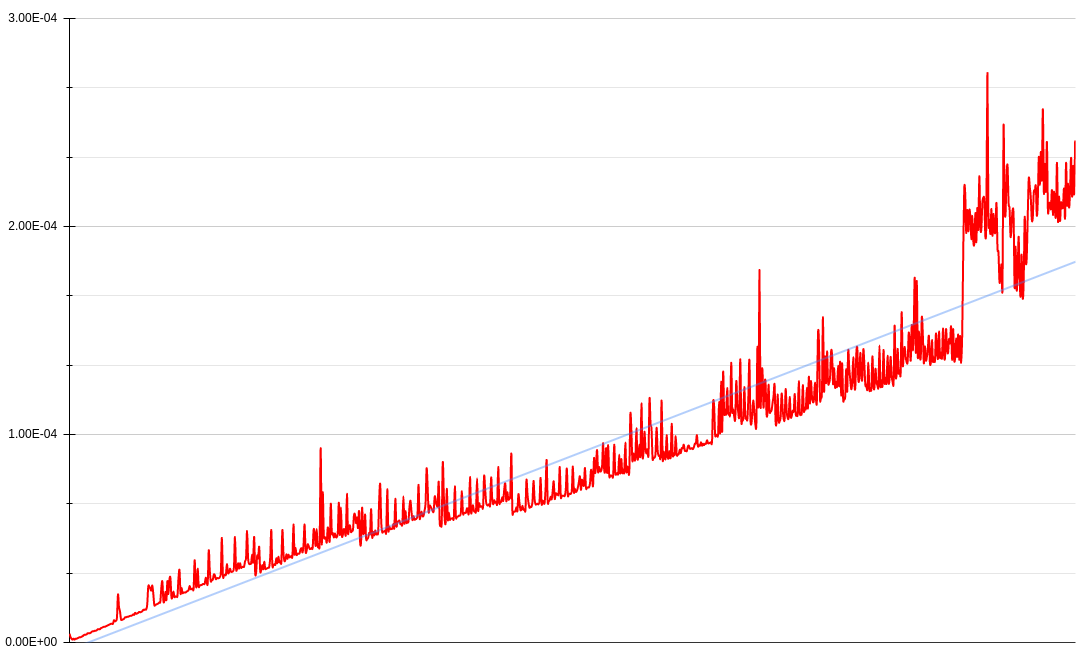
Improve Performance: Memoization
For the second improvement, I focused on performance once more. As the Python interpreter sets a maximum recursion limit to prevent infinite recursion, it also means that – using recursion – there is only a certain amount of series that can be calculated before a RecursionError is thrown. Personally I didn’t want to manually set the recursion limit as that won’t scale. So I discarded the tail recursion implementation and added a memoization decorator to the original recursion implementation to maximize the cache hit-miss ratio.
| |
Thanks to the dictionary’s O(1) lookup backbone but O(n) space complexity, it looks like we can somewhat maintain a low profile as n -> ∞. Roughly, 95-percentile of computations are around 0.0000045 seconds and 99-th percentile of these small computation set are around 0.0000066 seconds.
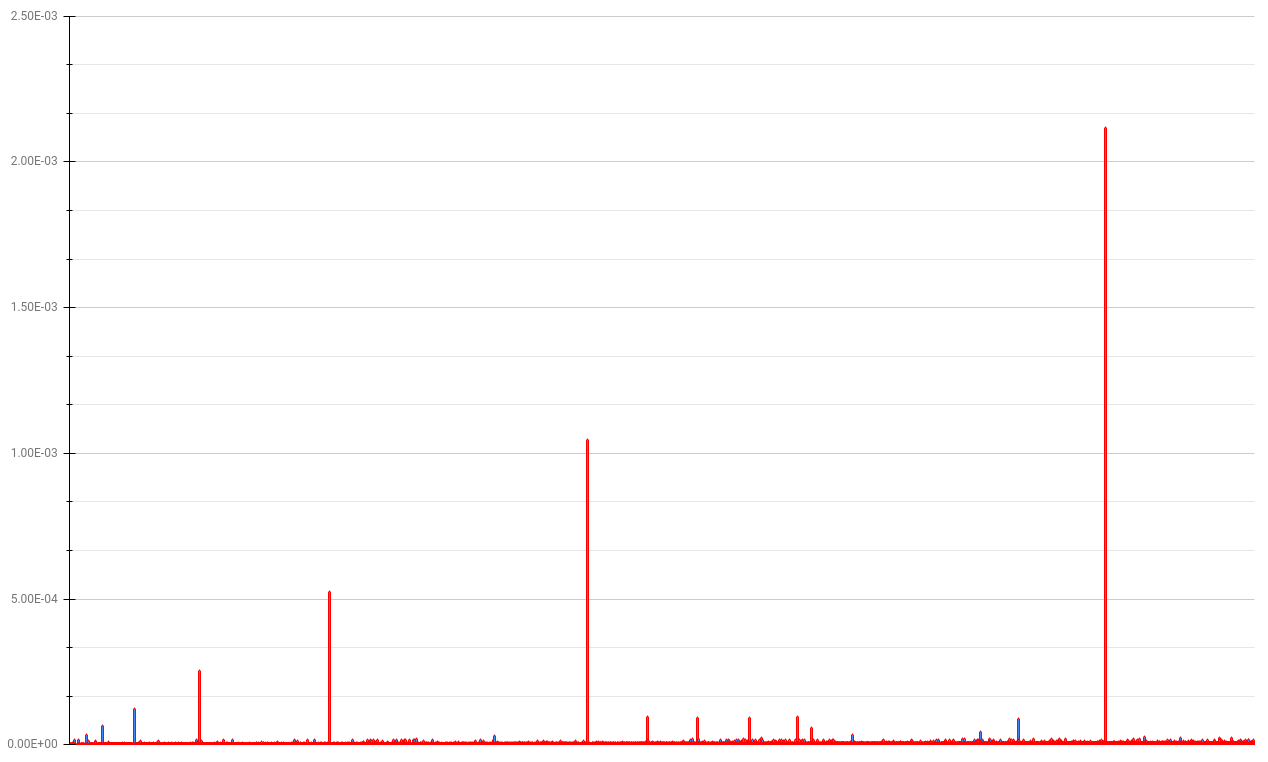
Incidentally, take a look at these “spikes”.
These “spike” patterns are derived from how a dictionary object works in the background to ensure the lookup algorithm does not slow down when it’s nearly full. Although I don’t fully understand how Python dictionaries internally work yet, my understanding is that when a dictionary is approximately 2/3 full, it resizes and copies over the hash table entries (w/o “dummy” entries - which are essentially placeholder entries that were deleted). Due to the copying that takes place, there is a spike in latency as a dictionary grows in size.
Improve Space: Iteration
For the third improvement, I focused on space. With the memoization technique, the interim cache is bounded by the space of the given memory. Since i+1th is derived from ith and i-1th, we technically don’t need to cache all entries upto ith.
I implemented a generator to iteratively update two constants i and j.
| |
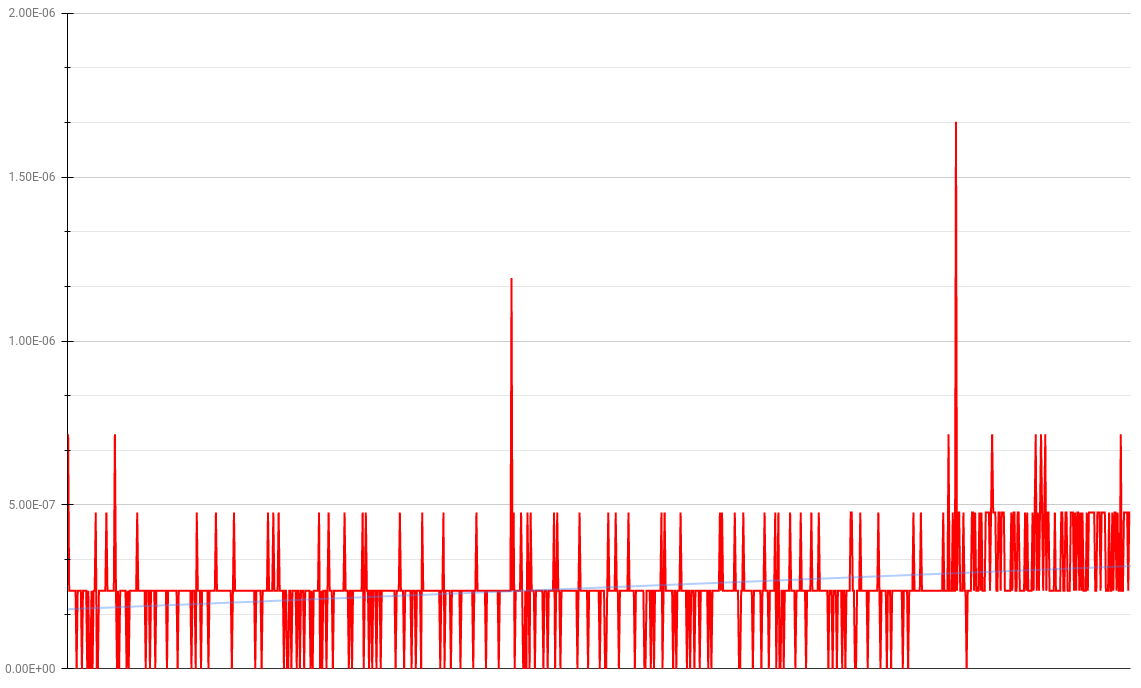
This implementation computes each sequence around constant 3e-7 seconds.
Improve Code: No Loop
For the last improvement, I tried removing loops entirely. I found this neat equation for computing Fibonacci sequence based on approximation.
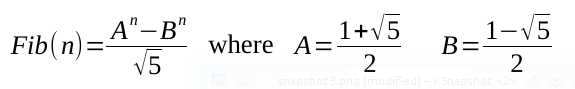
| |
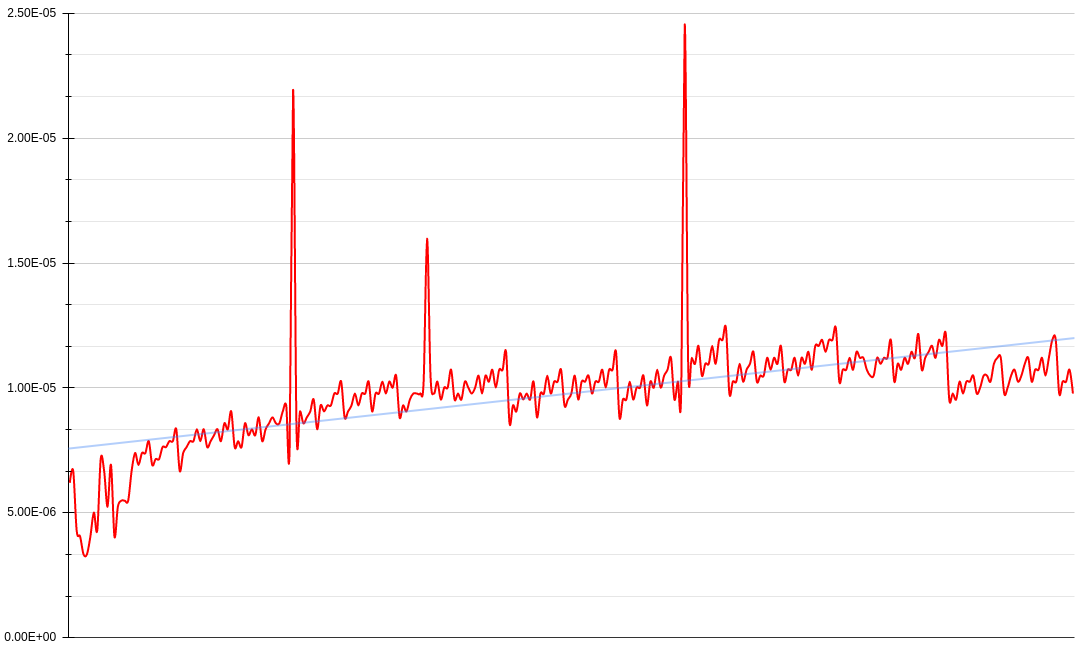
But even without much performance gains from the iterator pattern, there is a bigger scaling issue at hand. Because this algorithm is reliant on approximating the nth Fibonacci number, it also means the approximation is conditional on the precision of the float/Decimal. For example, this is how precision affects the range of the sequence.
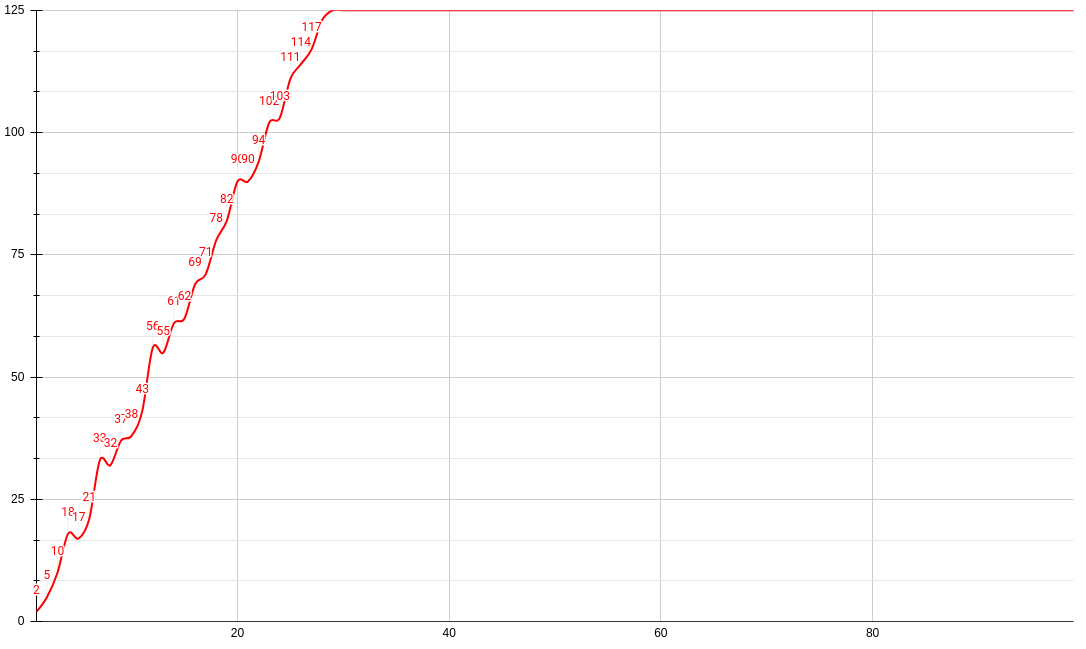
After a decimal point precision of 29, this algorithm fails to accurately calculate after the 125th Fibonacci sequence (which is around 59 septillion). This is probably due to the language constraints and how computers work with floating points. But although this improvement is done at a constant O(1) time complexity, it is infeasible due to precision.