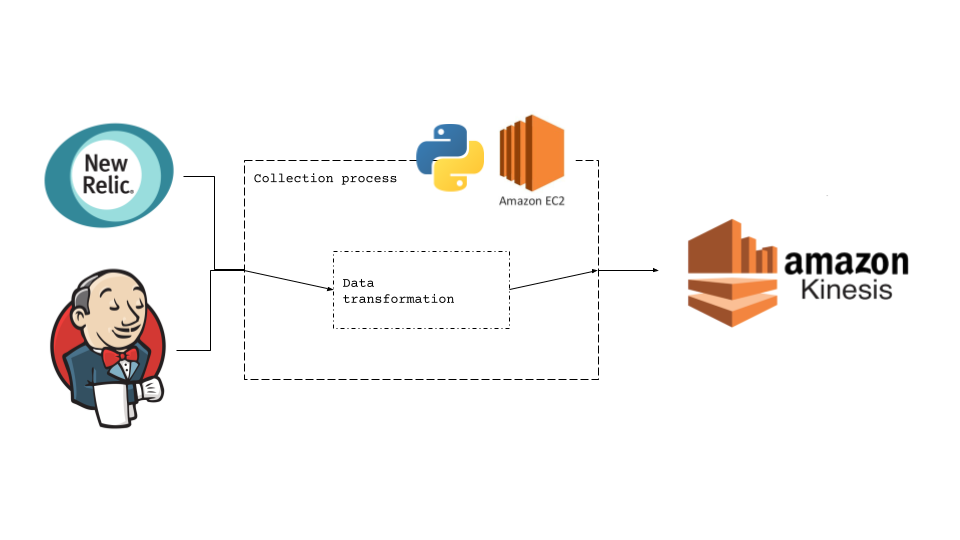
The other day at work, I was tasked in writing a simple data collection routine that pulled data from a New Relic API and a Jenkins plugin. This was an easy task as it’s a straightforward JSON response → apply some transformations → forward to an Amazon Kinesis topic → register this process to a cron.
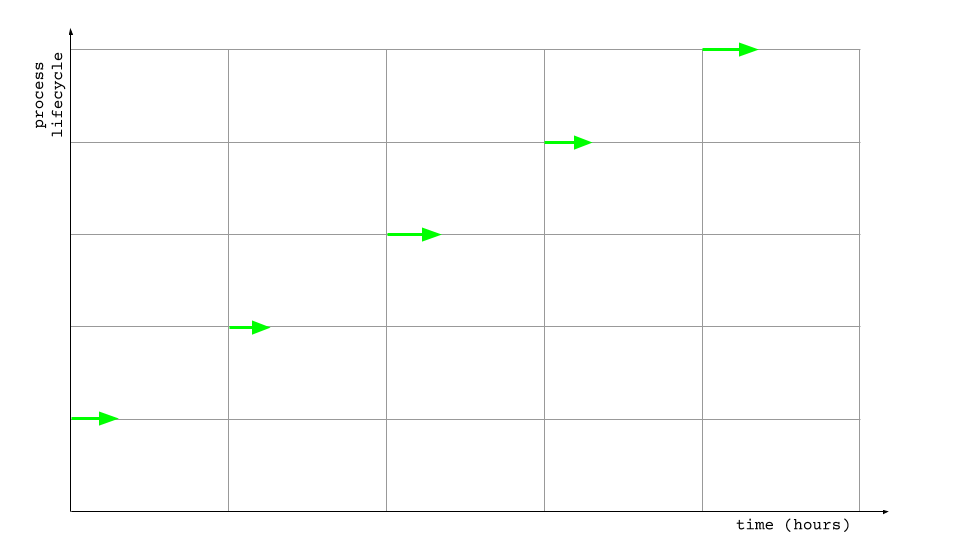
Once deployed, this was the observed behavior where each job cycle would terminate well below its’ one hour time budget.
But after a while, this behavior started to emerge.
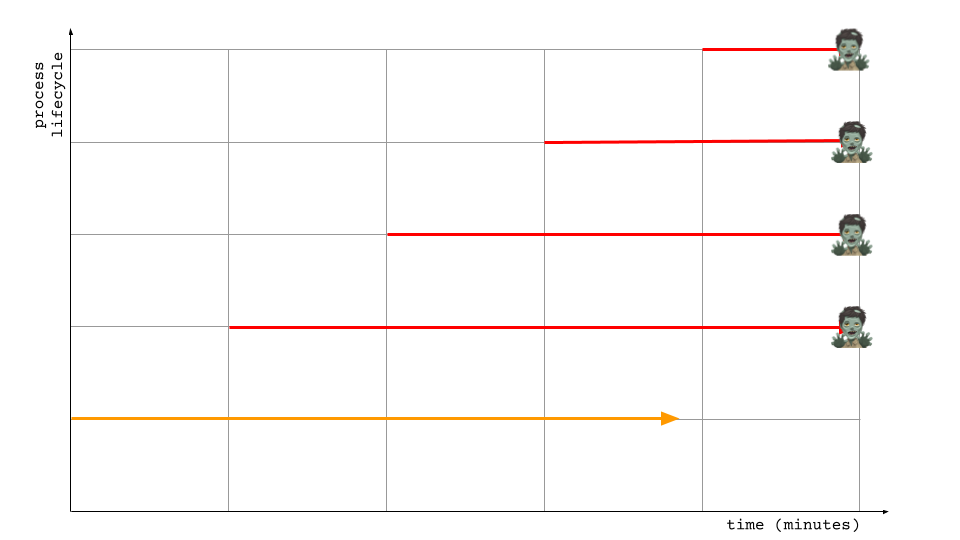
After investigation, I found that the code design was probably the major factor as it was written to be sequential for each API requests and synchronous so network requests are blocking call. This design had worked for the initial requirements of one execution per hour; but couldn’t scale well as requirements were added and frequency changed to per minute.
The easiest way to fix was by refactoring the collection logic to be multi-threaded. Albeit in Python, multithreading is not actually done in parallel but more based on context-switching a single thread. Even so, despite not being able to achieve perfect parallelism, concurrency would still be useful for the network blocks. The resulting improvements roughly looks like below to instead of managing individual Thread objects from the threading module, I opted to go with multiprocessing.Pool for the compute transformations and ThreadPoolExecutor for network requests.
| |