An anagram, by definition, is a string formed by the rearrangement of another verbatim composition. For example, given a list of words ["a", "ab", "ba", "apple", "paple"], the answer would be a nested list of [{"a"}, {"ab", "ba"}, {"apple", "paple"}] in any unsorted, insignificant order. This roughly infers that:
The atomic composition of a string must be identical to its anagram.
The length of a string must be equal to its’ anagram’s length.
The longest substring must appear in its’ anagram.
A sorted string must be identical to its sorted anagram. For instance, to determine whether “dog” is an anagram of “god”, we can sort both strings and assert the equality of the two. But although a linear string match would achieve the goal, let’s utilize hashing to transform sorted strings into a set of (hash, length), which we can use to identify future anagram test candidates with one of the two properties.
First, let’s begin by defining a substring block, b_i, of length n as b_i := c_i .. c_(i+n). And then group a string into smaller substrings of equal length n as f := (b_0 * X(0 .. n-1)) + b_1 * X(0 .. 2n-1). And finally, recursively hash the leaves (substrings) with a hash function H until the root node is calculated - the Merkle root. For example, using the earlier “dog” and “god” example, we can consider each character to be the leaves and construct two Merkle trees. After two strings are sorted and Merkle trees constructed, we can see the identity by comparing the Merkle root nodes. For this example, I used the MD5 digestion algorithm as my weak hash function.
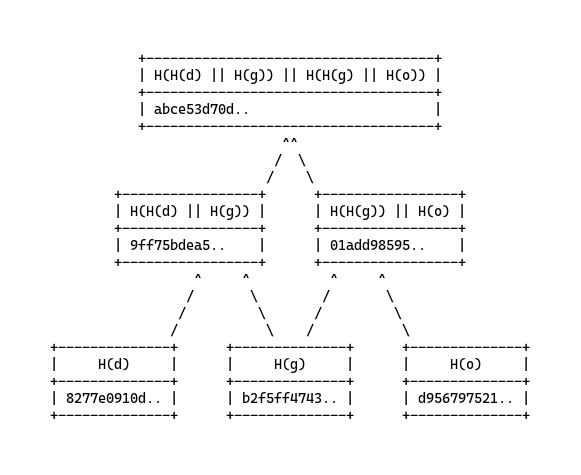
With these trees and the length properties, we can derive whether a test string is an anagram by matching against the length and then by the root hash.
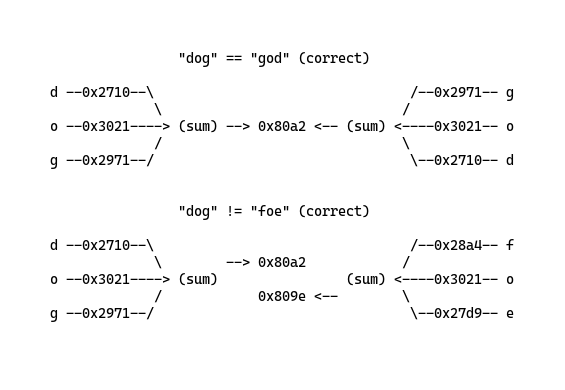
But going one more step, can a string be expressed in something different other than just another string? A string is a series of characters - and a character can be represented in fixed bits. And bits can be numeric. So we can make another conclusion that a string is a series of characters and also a series of numbers - of which can be arithmetically summed to create a fingerprint. This means that anagrams must have equal sums.

But as you may have already noticed, this design suffers if two or more different words can be summed to the same number. For example, “dog” and “foe” would yield the same sum:

This is due to the fact that a sum does not discriminate against the added elements (like how 1 + 1 = 2 just as 2 + 0 = 2). But we can fix the sum collision issue by introducing a negative feedback loop to counter the weight of each individual composition. Any counter function is fine, but I have decided to go with a simple square function, f(x) = x**2. Now “dog” and “god” are correctly identified, while “foe” is not.